README
Slonik



![]()

A battle-tested PostgreSQL client with strict types, detailed logging and assertions.
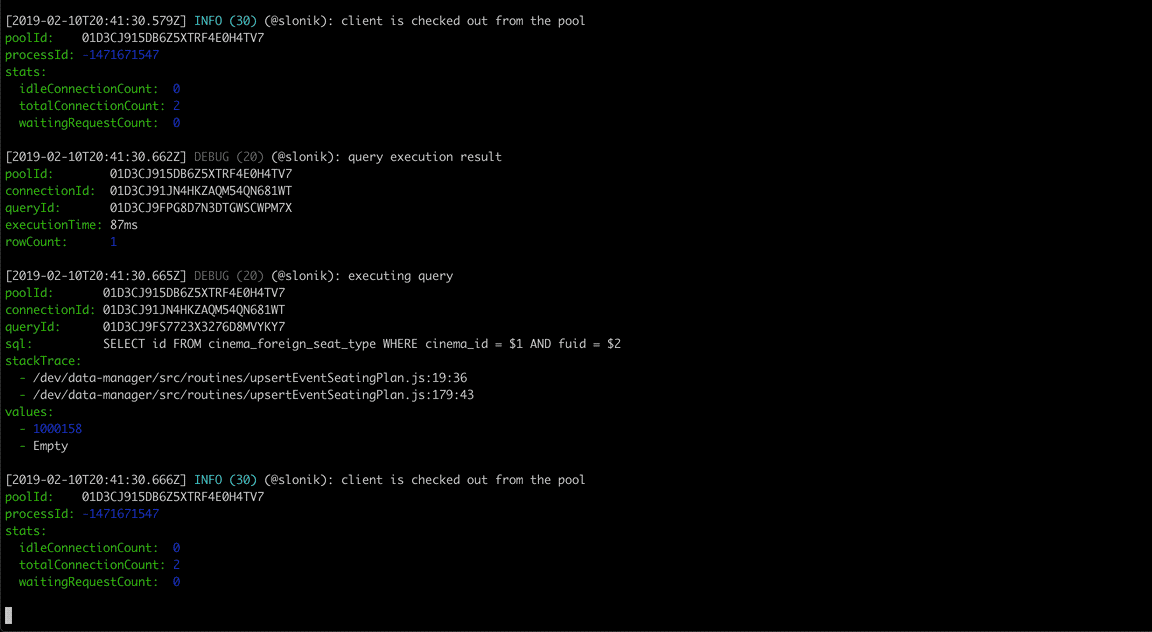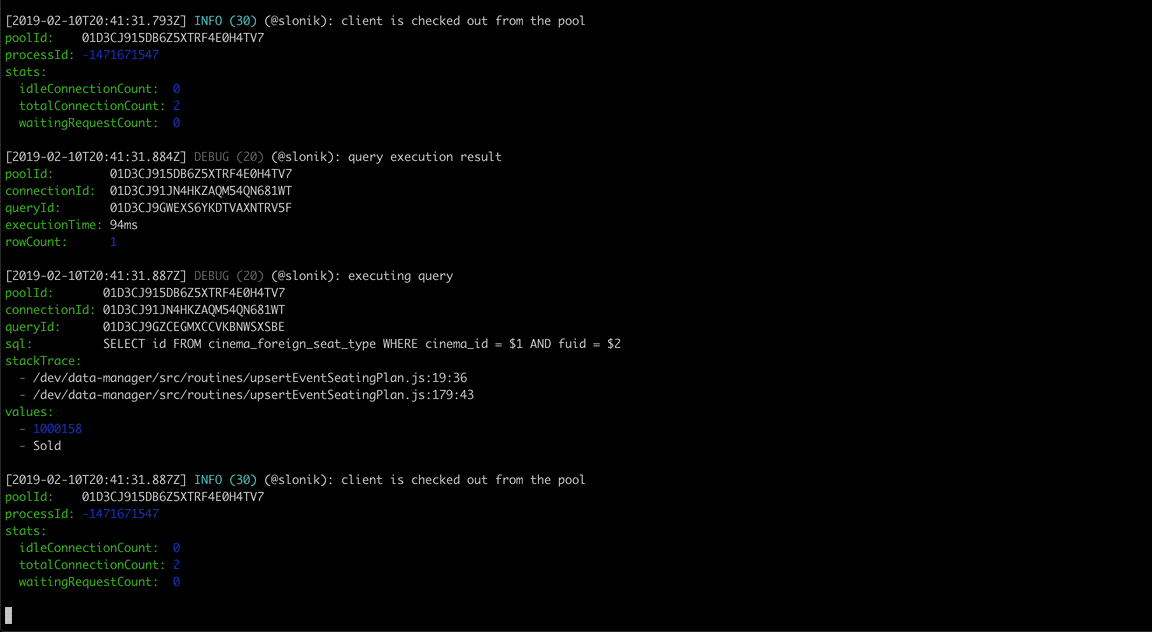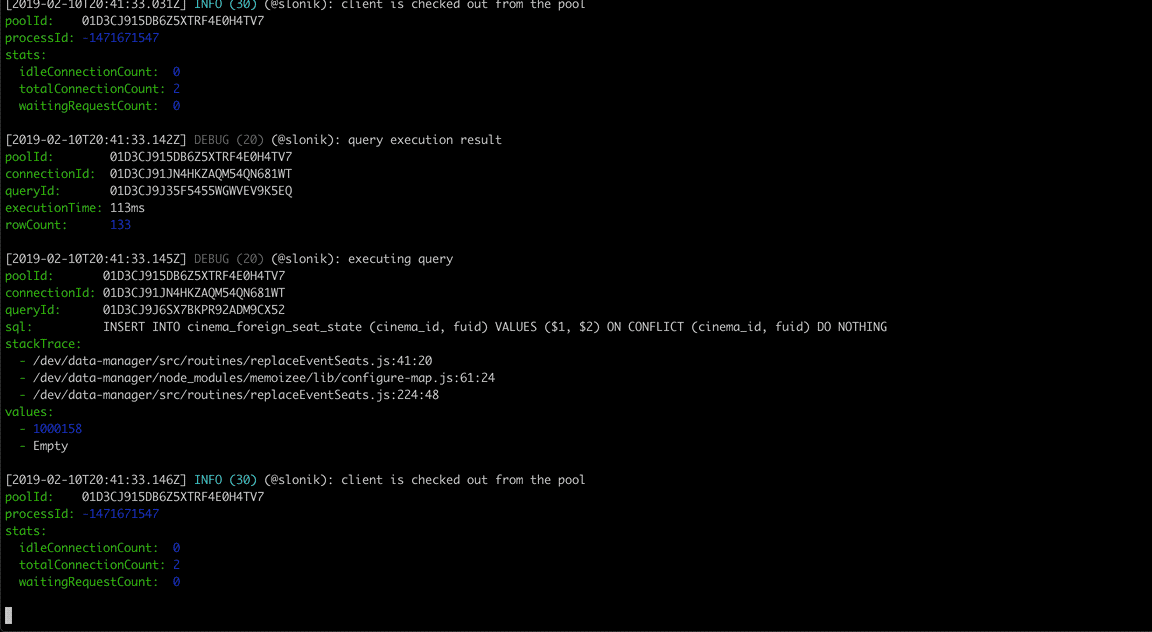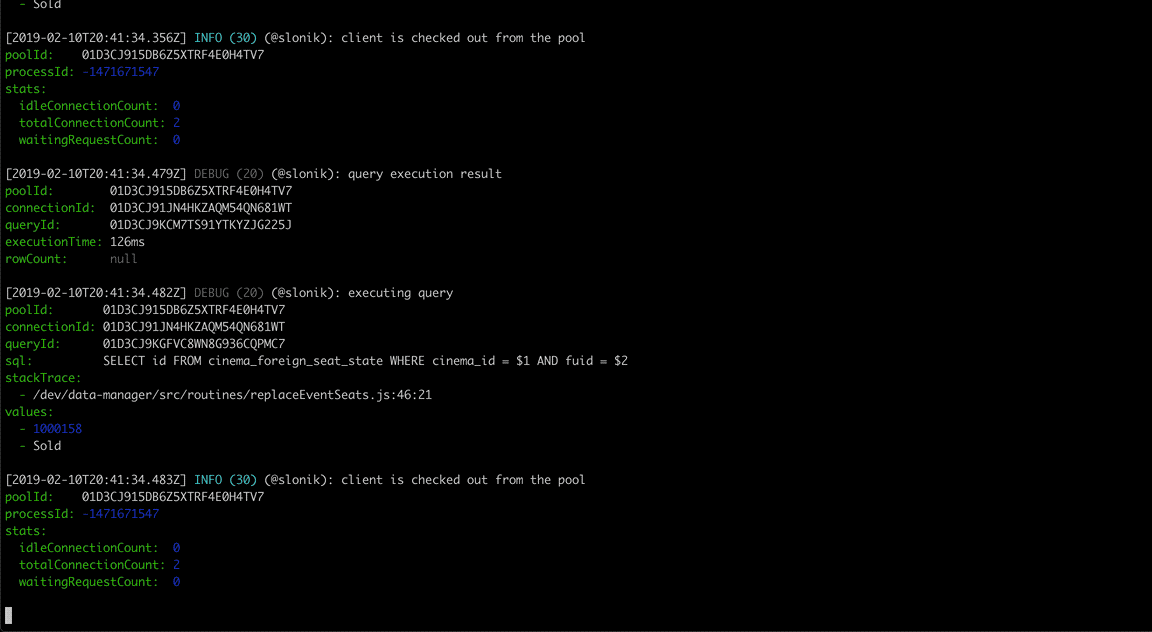
(The above GIF shows Slonik producing query logs. Slonik produces logs using Roarr. Logs include stack trace of the actual query invocation location and values used to execute the query.)
Sponsors
If you value my work and want to see Slonik and many other of my Open-Source projects to be continuously improved, then please consider becoming a patron:

![]()
Principles
- Promotes writing raw SQL.
- Discourages ad-hoc dynamic generation of SQL.
Read: Stop using Knex.js
Note: Using this project does not require TypeScript or Flow. It is a regular ES6 module. Ignore the type definitions used in the documentation if you do not use a type system.
Features
- Assertions and type safety
- Safe connection handling.
- Safe transaction handling.
- Safe value interpolation.
- Transaction nesting.
- Detailed logging.
- Asynchronous stack trace resolution.
- Middlewares.
- Mapped errors.
- ESLint plugin.
Contents
- Slonik
- Sponsors
- Principles
- Features
- Contents
- About Slonik
- Documentation
- Usage
- How are they different?
- Type parsers
- Interceptors
- Community interceptors
- Recipes
sqltag- Value placeholders
- Query building
- Query methods
- Error handling
- Original
node-postgreserror - Handling
BackendTerminatedError - Handling
CheckIntegrityConstraintViolationError - Handling
ConnectionError - Handling
DataIntegrityError - Handling
ForeignKeyIntegrityConstraintViolationError - Handling
NotFoundError - Handling
NotNullIntegrityConstraintViolationError - Handling
QueryCancelledError - Handling
UniqueIntegrityConstraintViolationError
- Original
- Types
- Debugging
- Syntax Highlighting
About Slonik
Battle-Tested
Slonik began as a collection of utilities designed for working with node-postgres. We continue to use node-postgres as it provides a robust foundation for interacting with PostgreSQL. However, what once was a collection of utilities has since grown into a framework that abstracts repeating code patterns, protects against unsafe connection handling and value interpolation, and provides rich debugging experience.
Slonik has been battle-tested with large data volumes and queries ranging from simple CRUD operations to data-warehousing needs.
Origin of the name

The name of the elephant depicted in the official PostgreSQL logo is Slonik. The name itself is derived from the Russian word for "little elephant".
Read: The History of Slonik, the PostgreSQL Elephant Logo
Repeating code patterns and type safety
Among the primary reasons for developing Slonik, was the motivation to reduce the repeating code patterns and add a level of type safety. This is primarily achieved through the methods such as one, many, etc. But what is the issue? It is best illustrated with an example.
Suppose the requirement is to write a method that retrieves a resource ID given values defining (what we assume to be) a unique constraint. If we did not have the aforementioned convenience methods available, then it would need to be written as:
// @flow
import {
sql
} from 'slonik';
import type {
DatabaseConnectionType
} from 'slonik';
opaque type DatabaseRecordIdType = number;
const getFooIdByBar = async (connection: DatabaseConnectionType, bar: string): Promise<DatabaseRecordIdType> => {
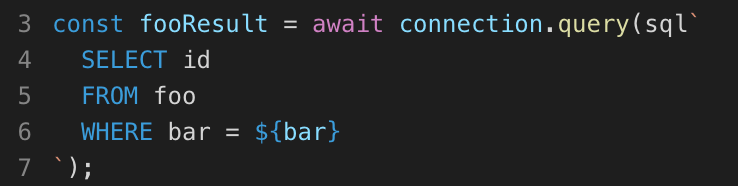
const fooResult = await connection.query(sql`
SELECT id
FROM foo
WHERE bar = ${bar}
`);
if (fooResult.rowCount === 0) {
throw new Error('Resource not found.');
}
if (fooResult.rowCount > 1) {
throw new Error('Data integrity constraint violation.');
}
return fooResult[0].id;
};
oneFirst method abstracts all of the above logic into:
const getFooIdByBar = (connection: DatabaseConnectionType, bar: string): Promise<DatabaseRecordIdType> => {
return connection.oneFirst(sql`
SELECT id
FROM foo
WHERE bar = ${bar}
`);
};
oneFirst throws:
NotFoundErrorif query returns no rowsDataIntegrityErrorif query returns multiple rowsDataIntegrityErrorif query returns multiple columns
This becomes particularly important when writing routines where multiple queries depend on the previous result. Using methods with inbuilt assertions ensures that in case of an error, the error points to the original source of the problem. In contrast, unless assertions for all possible outcomes are typed out as in the previous example, the unexpected result of the query will be fed to the next operation. If you are lucky, the next operation will simply break; if you are unlucky, you are risking data corruption and hard to locate bugs.
Furthermore, using methods that guarantee the shape of the results, allows us to leverage static type checking and catch some of the errors even before they executing the code, e.g.
const fooId = await connection.many(sql`
SELECT id
FROM foo
WHERE bar = ${bar}
`);
await connection.query(sql`
DELETE FROM baz
WHERE foo_id = ${fooId}
`);
Static type check of the above example will produce a warning as the fooId is guaranteed to be an array and binding of the last query is expecting a primitive value.
Protecting against unsafe connection handling
Slonik only allows to check out a connection for the duration of the promise routine supplied to the pool#connect() method.
The primary reason for implementing only this connection pooling method is because the alternative is inherently unsafe, e.g.
// Note: This example is using unsupported API.
const main = async () => {
const connection = await pool.connect();
await connection.query(sql`SELECT foo()`);
await connection.release();
};
In this example, if SELECT foo() produces an error, then connection is never released, i.e. the connection remains to hang.
A fix to the above is to ensure that connection#release() is always called, i.e.
// Note: This example is using unsupported API.
const main = async () => {
const connection = await pool.connect();
let lastExecutionResult;
try {
lastExecutionResult = await connection.query(sql`SELECT foo()`);
} finally {
await connection.release();
}
return lastExecutionResult;
};
Slonik abstracts the latter pattern into pool#connect() method.
const main = () => {
return pool.connect((connection) => {
return connection.query(sql`SELECT foo()`);
});
};
Connection is always released back to the pool after the promise produced by the function supplied to connect() method is either resolved or rejected.
Protecting against unsafe transaction handling
Just like in the unsafe connection handling described above, Slonik only allows to create a transaction for the duration of the promise routine supplied to the connection#transaction() method.
connection.transaction(async (transactionConnection) => {
await transactionConnection.query(sql`INSERT INTO foo (bar) VALUES ('baz')`);
await transactionConnection.query(sql`INSERT INTO qux (quux) VALUES ('quuz')`);
});
This pattern ensures that the transaction is either committed or aborted the moment the promise is either resolved or rejected.
Protecting against unsafe value interpolation
SQL injections are one of the most well known attack vectors. Some of the biggest data leaks were the consequence of improper user-input handling. In general, SQL injections are easily preventable by using parameterization and by restricting database permissions, e.g.
// Note: This example is using unsupported API.
connection.query('SELECT $1', [
userInput
]);
In this example, the query text (SELECT $1) and parameters (value of the userInput) are passed to the PostgreSQL server where the parameters are safely substituted into the query. This is a safe way to execute a query using user-input.
The vulnerabilities appear when developers cut corners or when they do not know about parameterization, i.e. there is a risk that someone will instead write:
// Note: This example is using unsupported API.
connection.query('SELECT \'' + userInput + '\'');
As evident by the history of the data leaks, this happens more often than anyone would like to admit. This is especially a big risk in Node.js community, where predominant number of developers are coming from frontend and have not had training working with RDBMSes. Therefore, one of the key selling points of Slonik is that it adds multiple layers of protection to prevent unsafe handling of user-input.
To begin with, Slonik does not allow to run plain-text queries.
connection.query('SELECT 1');
The above invocation would produce an error:
TypeError: Query must be constructed using
sqltagged template literal.
This means that the only way to run a query is by constructing it using sql tagged template literal, e.g.
connection.query(sql`SELECT 1`);
To add a parameter to the query, user must use template literal placeholders, e.g.
connection.query(sql`SELECT ${userInput}`);
Slonik takes over from here and constructs a query with value bindings, and sends the resulting query text and parameters to the PostgreSQL. As sql tagged template literal is the only way to execute the query, it adds a strong layer of protection against accidental unsafe user-input handling due to limited knowledge of the SQL client API.
As Slonik restricts user's ability to generate and execute dynamic SQL, it provides helper functions used to generate fragments of the query and the corresponding value bindings, e.g. sql.identifier, sql.join and sql.unnest. These methods generate tokens that the query executor interprets to construct a safe query, e.g.
connection.query(sql`
SELECT ${sql.identifier(['foo', 'a'])}
FROM (
VALUES
(
${sql.join(
[
sql.join(['a1', 'b1', 'c1'], sql`, `),
sql.join(['a2', 'b2', 'c2'], sql`, `)
],
sql`), (`
)}
)
) foo(a, b, c)
WHERE foo.b IN (${sql.join(['c1', 'a2'], sql`, `)})
`);
This (contrived) example generates a query equivalent to:
SELECT "foo"."a"
FROM (
VALUES
($1, $2, $3),
($4, $5, $6)
) foo(a, b, c)
WHERE foo.b IN ($7, $8)
That is executed with the parameters provided by the user.
Finally, if there comes a day that you must generate a whole or a fragment of a query using string concatenation, then Slonik provides sql.raw method. However, even when using sql.raw, we derisk the dangers of generating SQL by allowing developer to bind values only to the scope of the fragment that is being generated, e.g.
sql`
SELECT ${sql.raw('$1', ['foo'])}
`;
Allowing to bind values only to the scope of the SQL that is being generated reduces the amount of code that the developer needs to scan in order to be aware of the impact that the generated code can have. Continue reading Using sql.raw to generate dynamic queries to learn further about sql.raw.
To sum up, Slonik is designed to prevent accidental creation of queries vulnerable to SQL injections.
Documentation
Usage
Create connection
Use createPool to create a connection pool, e.g.
import {
createPool
} from 'slonik';
const pool = createPool('postgres://');
Instance of Slonik connection pool can be then used to create a new connection, e.g.
pool.connect(async (connection) => {
await connection.query(sql`SELECT 1`);
});
The connection will be kept alive until the promise resolves (the result of the method supplied to connect()).
Refer to query method documentation to learn about the connection methods.
If you do not require having a persistent connection to the same backend, then you can directly use pool to run queries, e.g.
pool.query(sql`SELECT 1`);
Beware that in the latter example, the connection picked to execute the query is a random connection from the connection pool, i.e. using the latter method (without explicit connect()) does not guarantee that multiple queries will refer to the same backend.
API
/**
* @param connectionUri PostgreSQL [Connection URI](https://www.postgresql.org/docs/current/libpq-connect.html#LIBPQ-CONNSTRING).
*/
createPool(
connectionUri: string,
clientConfiguration: ClientConfigurationType
): DatabasePoolType;
/**
* @property captureStackTrace Dictates whether to capture stack trace before executing query. Middlewares access stack trace through query execution context. (Default: true)
* @property connectionTimeout: Timeout (in milliseconds) after which an error is raised if cannot cannot be established. (Default: 5000)
* @property idleTimeout Timeout (in milliseconds) after which idle clients are closed. Use 'DISABLE_TIMEOUT' constant to disable the timeout. (Default: 5000)
* @property interceptors An array of [Slonik interceptors](https://github.com/gajus/slonik#slonik-interceptors).
* @property maximumPoolSize Do not allow more than this many connections. Use 'DISABLE_TIMEOUT' constant to disable the timeout. (Default: 10)
* @property minimumPoolSize Add more server connections to pool if below this number. (Default: 1)
* @property typeParsers An array of [Slonik type parsers](https://github.com/gajus/slonik#slonik-type-parsers).
*/
type ClientConfigurationType = {|
+captureStackTrace?: boolean,
+connectionTimeout?: number,
+idleTimeout?: number,
+interceptors?: $ReadOnlyArray<InterceptorType>,
+maximumPoolSize?: number,
+minimumPoolSize?: number,
+typeParsers?: $ReadOnlyArray<TypeParserType>
|};
Example:
import {
createPool
} from 'slonik';
const pool = createPool('postgres://');
await pool.query(sql`SELECT 1`);
Default configuration
Default interceptors
None.
Check out slonik-interceptor-preset for an opinionated collection of interceptors.
Default type parsers
These type parsers are enabled by default:
| Type name | Implemnetation |
|---|---|
int8 |
Produces an integer. |
interval |
Produces interval in seconds (integer). |
timestamp |
Produces a unix timestamp (in milliseconds). |
timestamptz |
Produces a unix timestamp (in milliseconds). |
To disable the default type parsers, pass an empty array, e.g.
createPool('postgres://', {
typeParsers: []
});
You can create default type parser collection using createTypeParserPreset, e.g.
import {
createTypeParserPreset
} from 'slonik';
createPool('postgres://', {
typeParsers: [
...createTypeParserPreset()
]
});
Checking out a client from the connection pool
Slonik only allows to check out a connection for the duration of the promise routine supplied to the pool#connect() method.
import {
createPool
} from 'slonik';
const pool = createPool('postgres://localhost');
const result = await pool.connect(async (connection) => {
await connection.query(sql`SELECT 1`);
await connection.query(sql`SELECT 2`);
return 'foo';
});
result;
// 'foo'
Connection is released back to the pool after the promise produced by the function supplied to connect() method is either resolved or rejected.
Read: Protecting against unsafe connection handling
How are they different?
pg vs slonik
pg is built intentionally to provide unopinionated, minimal abstraction and encourages use of other modules to implement convenience methods.
Slonik is built on top of pg and it provides convenience methods for building queries and querying data.
Work on pg began on Tue Sep 28 22:09:21 2010. It is authored by Brian Carlson.
pg-promise vs slonik
As the name suggests, pg-promise was originally built to enable use of pg module with promises (at the time, pg only supported Continuation Passing Style (CPS), i.e. callbacks). Since then pg-promise added features for connection/ transaction handling, a powerful query-formatting engine and a declarative approach to handling query results.
The primary difference between Slonik and pg-promise:
- Slonik does not allow to execute raw text queries. Slonik queries can only be constructed using
sqltagged template literals. This design protects against unsafe value interpolation. - Slonik implements interceptor API (middleware). Middlewares allow to modify connection handling, override queries and modify the query results. Example Slonik interceptors include field name transformation, query normalization and query benchmarking.
- Slonik implements transaction nesting.
Other differences are primarily in how the equivalent features are imlemented, e.g.
pg-promise |
Slonik |
|---|---|
| Custom type formatting. | Not available in Slonik. The current proposal is to create an interceptor that would have access to the query fragment constructor. |
| formatting filters | Slonik tagged template value expressions to construct query fragments and bind parameter values. |
| Query files. | Use sql.raw to load query files. |
| Tasks. | Use pool.connect. |
| Configurable transactions. | Not available in Slonik. Track this issue. |
| Events. | Use interceptors. |
When weighting which abstraction to use, it would be unfair not to consider that pg-promise is a mature project with dozens of contributors. Meanwhile, Slonik is a young project (started in March 2017) that until recently was developed without active community input. However, if you do support the unique features that Slonik adds, the opinionated API design, and are not afraid of adopting a technology in its young days, then I warmly invite you to addopt Slonik and become a contributor to what I intend to make the standard PostgreSQL client in the Node.js community.
Work on pg-promise began Wed Mar 4 02:00:34 2015. It is authored by Vitaly Tomilov.
Type parsers
Type parsers describe how to parse PostgreSQL types.
type TypeParserType = {|
+name: string,
+parse: (value: string) => *
|};
Example:
{
name: 'int8',
parse: (value) => {
return parseInt(value, 10);
}
}
Note: Unlike pg-types that uses OIDs to identify types, Slonik identifies types using their names.
Use this query to find type names:
SELECT
typname
FROM pg_type
ORDER BY typname ASC
Type parsers are configured using typeParsers client configuration.
Read: Default type parsers.
Built-in type parsers
| Type name | Implemnetation | Factory function name |
|---|---|---|
date |
Produces a literal date as a string (format: YYYY-MM-DD). | createDateTypeParser |
int8 |
Produces an integer. | createBigintTypeParser |
interval |
Produces interval in seconds (integer). | createIntervalTypeParser |
numeric |
Produces a float. | createNumericTypeParser |
timestamp |
Produces a unix timestamp (in milliseconds). | createTimestampTypeParser |
timestamptz |
Produces a unix timestamp (in milliseconds). | createTimestampWithTimeZoneTypeParser |
Built-in type parsers can be created using the exported factory functions, e.g.
import {
createTimestampTypeParser
} from 'slonik';
createTimestampTypeParser();
// {
// name: 'timestamp',
// parse: (value) => {
// return value === null ? value : Date.parse(value);
// }
// }
Interceptors
Functionality can be added to Slonik client by adding interceptors (middleware).
Interceptors are configured using client configuration, e.g.
import {
createPool
} from 'slonik';
const interceptors = [];
const connection = createPool('postgres://', {
interceptors
});
Interceptors are executed in the order they are added.
Read: Default interceptors.
Interceptor methods
Interceptor is an object that implements methods that can change the behaviour of the database client at different stages of the connection life-cycle
type InterceptorType = {|
+afterPoolConnection?: (
connectionContext: ConnectionContextType,
connection: DatabasePoolConnectionType
) => MaybePromiseType<void>,
+afterQueryExecution?: (
queryContext: QueryContextType,
query: QueryType,
result: QueryResultType<QueryResultRowType>
) => MaybePromiseType<QueryResultType<QueryResultRowType>>,
+beforePoolConnection?: (
connectionContext: ConnectionContextType
) => MaybePromiseType<?DatabasePoolType>,
+beforePoolConnectionRelease?: (
connectionContext: ConnectionContextType,
connection: DatabasePoolConnectionType
) => MaybePromiseType<void>,
+beforeQueryExecution?: (
queryContext: QueryContextType,
query: QueryType
) => MaybePromiseType<QueryResultType<QueryResultRowType>> | MaybePromiseType<void>,
+queryExecutionError?: (
queryContext: QueryContextType,
query: QueryType,
error: SlonikError
) => MaybePromiseType<void>,
+transformQuery?: (
queryContext: QueryContextType,
query: QueryType
) => QueryType,
+transformRow?: (
queryContext: QueryContextType,
query: QueryType,
row: QueryResultRowType,
fields: $ReadOnlyArray<FieldType>
) => QueryResultRowType
|};
afterPoolConnection
Executed after a connection is acquired from the connection pool (or a new connection is created), e.g.
const pool = createPool('postgres://');
// Interceptor is executed here. ↓
pool.connect();
afterQueryExecution
afterQueryExecution must return the result of the query, which will be passed down to the client.
Use afterQuery to modify the query result.
Note: When query is executed using stream, then afterQuery is called with empty result set and does not affect the query result.
beforeQueryExecution
This function can optionally return a direct result of the query which will cause the actual query never to be executed.
beforePoolConnectionRelease
Executed before connection is released back to the connection pool, e.g.
const pool = await createPool('postgres://');
pool.connect(async () => {
await 1;
// Interceptor is executed here. ↓
});
queryExecutionError
Executed if query execution produces an error.
Use queryExecutionError to log and/ or re-throw another error.
transformQuery
Executed before beforeQueryExecution.
Transforms query.
transformRow
Executed for each row.
Transforms row.
Use transformRow to modify the query result.
Community interceptors
| Name | Description |
|---|---|
slonik-interceptor-field-name-transformation |
Transforms Slonik query result field names. |
slonik-interceptor-query-benchmarking |
Benchmarks Slonik queries. |
slonik-interceptor-query-logging |
Logs Slonik queries. |
slonik-interceptor-query-normalisation |
Normalises Slonik queries. |
Check out slonik-interceptor-preset for an opinionated collection of interceptors.
Recipes
Inserting large number of rows
Slonik provides sql.tupleList helper function to generate a list of tuples that can be used in the INSERT values expression, e.g.
await connection.query(sql`
INSERT INTO (foo, bar, baz)
VALUES ${sql.tupleList([
[1, 2, 3],
[4, 5, 6]
])}
`);
Produces:
{
sql: 'INSERT INTO (foo, bar, baz) VALUES ($1, $2, $3), ($4, $5, $6)',
values: [
1,
2,
3,
4,
5,
6
]
}
There are 2 downsides to this approach:
- The generated SQL is dynamic and will vary depending on the input.
- You will not be able to track query stats.
- Query parsing time increases with the query size.
- There is a maximum number of parameters that can be bound to the statement (65535).
As an alternative, we can use sql.unnest to create a set of rows using unnest. Using the unnest approach requires only 1 variable per every column; values for each column are passed as an array, e.g.
await connection.query(sql`
INSERT INTO (foo, bar, baz)
SELECT *
FROM ${sql.unnest(
[
[1, 2, 3],
[4, 5, 6]
],
[
'int4',
'int4',
'int4'
]
)}
`);
Produces:
{
sql: 'INSERT INTO (foo, bar, baz) SELECT * FROM unnest($1::int4[], $2::int4[], $2::int4[])',
values: [
[
1,
4
],
[
2,
5
],
[
3,
6
]
]
}
Inserting data this way ensures that the query is stable and reduces the amount of time it takes to parse the query.
Routing queries to different connections
If connection is initiated by a query (as opposed to a obtained explicitly using pool#connect()), then beforePoolConnection interceptor can be used to change the pool that will be used to execute the query, e.g.
const slavePool = createPool('postgres://slave');
const masterPool = createPool('postgres://master', {
interceptors: [
{
beforePoolConnection: (connectionContext, pool) => {
if (connectionContext.query && connectionContext.query.sql.includes('SELECT')) {
return slavePool;
}
return pool;
}
}
]
});
// This query will use `postgres://slave` connection.
masterPool.query(sql`SELECT 1`);
// This query will use `postgres://master` connection.
masterPool.query(sql`UPDATE 1`);
sql tag
sql tag serves two purposes:
- It is used to construct queries with bound parameter values (see Value placeholders).
- It used to generate dynamic query fragments (see Query building).
sql tag can be imported from Slonik package:
import {
sql
} from 'slonik';
Sometiems it may be desirable to construct a custom instance of sql tag. In those cases, you can use the createSqlTag factory, e.g.
import {
createSqlTag
} from 'slonik';
/**
* @typedef SqlTagConfiguration
*/
/**
* @param {SqlTagConfiguration} configuration
*/
const sql = createSqlTag(configuration);
Value placeholders
Tagged template literals
Slonik query methods can only be executed using sql tagged template literal, e.g.
import {
sql
} from 'slonik'
connection.query(sql`
SELECT 1
FROM foo
WHERE bar = ${'baz'}
`);
The above is equivalent to evaluating:
SELECT 1
FROM foo
WHERE bar = $1
query with 'baz' value binding.
Manually constructing the query
Manually constructing queries is not allowed.
There is an internal mechanism that checks to see if query was created using sql tagged template literal, i.e.
const query = {
sql: 'SELECT 1 FROM foo WHERE bar = $1',
type: 'SQL',
values: [
'baz'
]
};
connection.query(query);
Will result in an error:
Query must be constructed using
sqltagged template literal.
This is a security measure designed to prevent unsafe query execution.
Furthermore, a query object constructed using sql tagged template literal is frozen to prevent further manipulation.
Nesting sql
sql tagged template literals can be nested, e.g.
const query0 = sql`SELECT ${'foo'} FROM bar`;
const query1 = sql`SELECT ${'baz'} FROM (${query0})`;
Produces:
{
sql: 'SELECT $1 FROM (SELECT $2 FROM bar)',
values: [
'baz',
'foo'
]
}
Query building
Queries are built using methods of the sql tagged template literal.
If this is your first time using Slonik, read Dynamically generating SQL queries using Node.js.
sql.array
(
values: $ReadOnlyArray<PrimitiveValueExpressionType>,
memberType: TypeNameIdentifierType | SqlTokenType
) => ArraySqlTokenType;
Creates an array value binding, e.g.
await connection.query(sql`
SELECT (${sql.array([1, 2, 3], 'int4')})
`);
Produces:
{
sql: 'SELECT $1::"int4"[]',
values: [
[
1,
2,
3
]
]
}
sql.array memberType
If memberType is a string (TypeNameIdentifierType), then it is treated as a type name identifier and will be quoted using double quotes, i.e. sql.array([1, 2, 3], 'int4') is equivalent to $1::"int4"[]. The implication is that keywrods that are often used interchangeably with type names are not going to work, e.g. int4 is a type name identifier and will work. However, int is a keyword and will not work. You can either use type name identifiers or you can construct custom member using sql.raw, e.g.
await connection.query(sql`
SELECT (${sql.array([1, 2, 3], sql`int[]`)})
`);
Produces:
{
sql: 'SELECT $1::int[]',
values: [
[
1,
2,
3
]
]
}
sql.array vs sql.join
Unlike sql.join, sql.array generates a stable query of a predictable length, i.e. regardless of the number of values in the array, the generated query remains the same:
- Having a stable query enables
pg_stat_statementsto aggregate all query execution statistics. - Keeping the query length short reduces query parsing time.
Example:
sql`SELECT id FROM foo WHERE id IN (${sql.join([1, 2, 3], sql`, `)})`;
sql`SELECT id FROM foo WHERE id NOT IN (${sql.join([1, 2, 3], sql`, `)})`;
Is equivalent to:
sql`SELECT id FROM foo WHERE id = ANY(${sql.array([1, 2, 3], 'int4')})`;
sql`SELECT id FROM foo WHERE id != ALL(${sql.array([1, 2, 3], 'int4')})`;
Furthermore, unlike sql.join, sql.array can be used with an empty array of values. In short, sql.array should be preferred over sql.join when possible.
sql.binary
(
data: Buffer
) => BinarySqlTokenType;
Binds binary (bytea) data, e.g.
await connection.query(sql`
SELECT ${sql.binary(Buffer.from('foo'))}
`);
Produces:
{
sql: 'SELECT $1',
values: [
Buffer.from('foo')
]
}
sql.identifier
(
names: $ReadOnlyArray<string>
) => IdentifierSqlTokenType;
Delimited identifiers are created by enclosing an arbitrary sequence of characters in double-quotes ("). To create create a delimited identifier, create an sql tag function placeholder value using sql.identifier, e.g.
sql`
SELECT 1
FROM ${sql.identifier(['bar', 'baz'])}
`;
Produces:
{
sql: 'SELECT 1 FROM "bar"."bar"',
values: []
}
sql.json
(
value: SerializableValueType
) => JsonSqlTokenType;
Serializes value and binds it as a JSON string literal, e.g.
await connection.query(sql`
SELECT (${sql.json([1, 2, 3])})
`);
Produces:
{
sql: 'SELECT $1',
values: [
'[1,2,3]'
]
}
Difference from JSON.stringify
| Input | sql.json |
JSON.stringify |
|---|---|---|
undefined |
Throws InvalidInputError error. |
undefined |
null |
null |
"null" (string literal) |
sql.join
(
members: $ReadOnlyArray<SqlTokenType>,
glue: SqlTokenType
) => ListSqlTokenType;
Concatenates SQL expressions using glue separator, e.g.
await connection.query(sql`
SELECT ${sql.join([1, 2, 3], sql`, `)}
`);
Produces:
{
sql: 'SELECT $1, $2, $3',
values: [
1,
2,
3
]
}
sql.join is the primary building block for most of the SQL, e.g.
Boolean expressions:
sql`
SELECT ${sql.join([1, 2], sql` AND `)}
`
// SELECT $1 AND $2
Tuple:
sql`
SELECT (${sql.join([1, 2], sql`, `)})
`
// SELECT ($1, $2)
Tuple list:
sql`
SELECT ${sql.join(
[
sql`(${sql.join([1, 2], sql`, `)})`,
sql`(${sql.join([3, 4], sql`, `)})`,
],
sql`, `
)}
`
// SELECT ($1, $2), ($3, $4)
Difference from JSON.stringify
| Input | sql.json |
JSON.stringify |
|---|---|---|
undefined |
Throws InvalidInputError error. |
undefined |
null |
null |
"null" (string literal) |
sql.raw
(
rawSql: string,
values?: $ReadOnlyArray<PrimitiveValueExpressionType>
) => RawSqlTokenType;
Danger! Read carefully: There are no known use cases for generating queries using sql.raw that aren't covered by nesting bound sql expressions or by one of the other existing query building methods. sql.raw exists as a mechanism to execute externally stored static (e.g. queries stored in files).
Raw/ dynamic SQL can be inlined using sql.raw, e.g.
sql`
SELECT 1
FROM ${sql.raw('"bar"')}
`;
Produces:
{
sql: 'SELECT 1 FROM "bar"',
values: []
}
The second parameter of the sql.raw can be used to bind positional parameter values, e.g.
sql`
SELECT ${sql.raw('$1', [1])}
`;
Produces:
{
sql: 'SELECT $1',
values: [
1
]
}
Named parameters
sql.raw supports named parameters, e.g.
sql`
SELECT ${sql.raw(':foo, :bar', {bar: 'BAR', foo: 'FOO'})}
`;
Produces:
{
sql: 'SELECT $1, $2',
values: [
'FOO',
'BAR'
]
}
Named parameters are matched using /[\s,(]:([a-z_]+)/g regex.
sql.unnest
(
tuples: $ReadOnlyArray<$ReadOnlyArray<PrimitiveValueExpressionType>>,
columnTypes: $ReadOnlyArray<string>
): UnnestSqlTokenType;
Creates an unnest expressions, e.g.
await connection.query(sql`
SELECT bar, baz
FROM ${sql.unnest(
[
[1, 'foo'],
[2, 'bar']
],
[
'int4',
'text'
]
)} AS foo(bar, baz)
`);
Produces:
{
sql: 'SELECT bar, baz FROM unnest($1::int4[], $2::text[]) AS foo(bar, baz)',
values: [
[
1,
2
],
[
'foo',
'bar'
]
]
}
Query methods
any
Returns result rows.
Example:
const rows = await connection.any(sql`SELECT foo`);
#any is similar to #query except that it returns rows without fields information.
anyFirst
Returns value of the first column of every row in the result set.
- Throws
DataIntegrityErrorif query returns multiple rows.
Example:
const fooValues = await connection.anyFirst(sql`SELECT foo`);
copyFromBinary
(
streamQuery: TaggedTemplateLiteralInvocationType,
tupleList: $ReadOnlyArray<$ReadOnlyArray<any>>,
columnTypes: $ReadOnlyArray<TypeNameIdentifierType>
) => Promise<null>;
Copies from a binary stream.
The binary stream is constructed using user supplied tupleList and columnTypes values.
Example:
const tupleList = [
[
1,
'baz'
],
[
2,
'baz'
]
];
const columnTypes = [
'int4',
'text'
];
await connection.copyFromBinary(
sql`
COPY foo
(
id,
baz
)
FROM STDIN BINARY
`,
tupleList,
columnTypes
);
Limitations
- Tuples cannot contain
NULLvalues.
Implementation notes
copyFromBinary implementation is designed to minimize the query execution time at the cost of increased script memory usage and execution time. This is achieved by separating data encoding from feeding data to PostgreSQL, i.e. all data passed to copyFromBinary is first encoded and then fed to PostgreSQL (contrast this to using a stream with encoding transformation to feed data to PostgreSQL).
Related documentation
many
Returns result rows.
- Throws
NotFoundErrorif query returns no rows.
Example:
const rows = await connection.many(sql`SELECT foo`);
manyFirst
Returns value of the first column of every row in the result set.
- Throws
NotFoundErrorif query returns no rows. - Throws
DataIntegrityErrorif query returns multiple columns.
Example:
const fooValues = await connection.many(sql`SELECT foo`);
maybeOne
Selects the first row from the result.
- Returns
nullif row is not found. - Throws
DataIntegrityErrorif query returns multiple rows.
Example:
const row = await connection.maybeOne(sql`SELECT foo`);
// row.foo is the result of the `foo` column value of the first row.
maybeOneFirst
Returns value of the first column from the first row.
- Returns
nullif row is not found. - Throws
DataIntegrityErrorif query returns multiple rows. - Throws
DataIntegrityErrorif query returns multiple columns.
Example:
const foo = await connection.maybeOneFirst(sql`SELECT foo`);
// foo is the result of the `foo` column value of the first row.
one
Selects the first row from the result.
- Throws
NotFoundErrorif query returns no rows. - Throws
DataIntegrityErrorif query returns multiple rows.
Example:
const row = await connection.one(sql`SELECT foo`);
// row.foo is the result of the `foo` column value of the first row.
Note:
I've been asked "What makes this different from knex.js
knex('foo').limit(1)?".knex('foo').limit(1)simply generates "SELECT * FROM foo LIMIT 1" query.knexis a query builder; it does not assert the value of the result. Slonik#oneadds assertions about the result of the query.
oneFirst
Returns value of the first column from the first row.
- Throws
NotFoundErrorif query returns no rows. - Throws
DataIntegrityErrorif query returns multiple rows. - Throws
DataIntegrityErrorif query returns multiple columns.
Example:
const foo = await connection.oneFirst(sql`SELECT foo`);
// foo is the result of the `foo` column value of the first row.
query
API and the result shape are equivalent to pg#query.
Example:
await connection.query(sql`SELECT foo`);
// {
// command: 'SELECT',
// fields: [],
// notices: [],
// oid: null,
// rowAsArray: false,
// rowCount: 1,
// rows: [
// {
// foo: 'bar'
// }
// ]
// }
stream
Streams query results.
Example:
await connection.stream(sql`SELECT foo`, (stream) => {
stream.on('data', (datum) => {
datum;
// {
// fields: [
// {
// name: 'foo',
// tableID: 0,
// columnID: 0,
// dataTypeID: 23,
// dataTypeSize: 4,
// dataTypeModifier: -1,
// format: 'text'
// }
// ],
// row: {
// foo: 'bar'
// }
// }
});
});
Note: Implemneted using pg-query-stream.
transaction
transaction method is used wrap execution of queries in START TRANSACTION and COMMIT or ROLLBACK. COMMIT is called if the transaction handler returns a promise that resolves; ROLLBACK is called otherwise.
transaction method can be used together with createPool method. When used to create a transaction from an instance of a pool, a new connection is allocated for the duration of the transaction.
const result = await connection.transaction(async (transactionConnection) => {
await transactionConnection.query(sql`INSERT INTO foo (bar) VALUES ('baz')`);
await transactionConnection.query(sql`INSERT INTO qux (quux) VALUES ('corge')`);
return 'FOO';
});
result === 'FOO';
Transaction nesting
Slonik uses SAVEPOINT to automatically nest transactions, e.g.
await connection.transaction(async (t1) => {
await t1.query(sql`INSERT INTO foo (bar) VALUES ('baz')`);
return t1.transaction((t2) => {
return t2.query(sql`INSERT INTO qux (quux) VALUES ('corge')`);
});
});
is equivalent to:
START TRANSACTION;
INSERT INTO foo (bar) VALUES ('baz');
SAVEPOINT slonik_savepoint_1;
INSERT INTO qux (quux) VALUES ('corge');
COMMIT;
Slonik automatically rollsback to the last savepoint if a query belonging to a transaction results in an error, e.g.
await connection.transaction(async (t1) => {
await t1.query(sql`INSERT INTO foo (bar) VALUES ('baz')`);
try {
await t1.transaction(async (t2) => {
await t2.query(sql`INSERT INTO qux (quux) VALUES ('corge')`);
return Promise.reject(new Error('foo'));
});
} catch (error) {
}
});
is equivalent to:
START TRANSACTION;
INSERT INTO foo (bar) VALUES ('baz');
SAVEPOINT slonik_savepoint_1;
INSERT INTO qux (quux) VALUES ('corge');
ROLLBACK TO SAVEPOINT slonik_savepoint_1;
COMMIT;
If error is unhandled, then the entire transaction is rolledback, e.g.
await connection.transaction(async (t1) => {
await t1.query(sql`INSERT INTO foo (bar) VALUES ('baz')`);
await t1.transaction(async (t2) => {
await t2.query(sql`INSERT INTO qux (quux) VALUES ('corge')`);
await t1.transaction(async (t3) => {
await t3.query(sql`INSERT INTO uier (grault) VALUES ('garply')`);
return Promise.reject(new Error('foo'));
});
});
});
is equivalent to:
START TRANSACTION;
INSERT INTO foo (bar) VALUES ('baz');
SAVEPOINT slonik_savepoint_1;
INSERT INTO qux (quux) VALUES ('corge');
SAVEPOINT slonik_savepoint_2;
INSERT INTO uier (grault) VALUES ('garply');
ROLLBACK TO SAVEPOINT slonik_savepoint_2;
ROLLBACK TO SAVEPOINT slonik_savepoint_1;
ROLLBACK;
Error handling
All Slonik errors extend from SlonikError, i.e. You can catch Slonik specific errors using the following logic.
import {
SlonikError
} from 'slonik';
try {
await query();
} catch (error) {
if (error instanceof SlonikError) {
// This error is thrown by Slonik.
}
}
Original node-postgres error
When error originates from node-postgres, the original error is available under originalError property.
This propery is exposed for debugging purposes only. Do not use it for conditional checks – it can change.
If you require to extract meta-data about a specific type of error (e.g. contraint violation name), raise a GitHub issue describing your use case.
Handling BackendTerminatedError
BackendTerminatedError is thrown when the backend is terminated by the user, i.e. pg_terminate_backend.
BackendTerminatedError must be handled at the connection level, i.e.
await pool.connect(async (connection0) => {
try {
await pool.connect(async (connection1) => {
const backendProcessId = await connection1.oneFirst(sql`SELECT pg_backend_pid()`);
setTimeout(() => {
connection0.query(sql`SELECT pg_cancel_backend(${backendProcessId})`)
}, 2000);
try {
await connection1.query(sql`SELECT pg_sleep(30)`);
} catch (error) {
// This code will not be executed.
}
});
} catch (error) {
if (error instanceof BackendTerminatedError) {
// Handle backend termination.
} else {
throw error;
}
}
});
Handling CheckIntegrityConstraintViolationError
CheckIntegrityConstraintViolationError is thrown when PostgreSQL responds with check_violation (23514) error.
Handling ConnectionError
ConnectionError is thrown when connection cannot be established to the PostgreSQL server.
Handling DataIntegrityError
To handle the case where the data result does not match the expectations, catch DataIntegrityError error.
import {
NotFoundError
} from 'slonik';
let row;
try {
row = await connection.one(sql`SELECT foo`);
} catch (error) {
if (error instanceof DataIntegrityError) {
console.error('There is more than one row matching the select criteria.');
} else {
throw error;
}
}
Handling ForeignKeyIntegrityConstraintViolationError
ForeignKeyIntegrityConstraintViolationError is thrown when PostgreSQL responds with foreign_key_violation (23503) error.
Handling NotFoundError
To handle the case where query returns less than one row, catch NotFoundError error.
import {
NotFoundError
} from 'slonik';
let row;
try {
row = await connection.one(sql`SELECT foo`);
} catch (error) {
if (!(error instanceof NotFoundError)) {
throw error;
}
}
if (row) {
// row.foo is the result of the `foo` column value of the first row.
}
Handling NotNullIntegrityConstraintViolationError
NotNullIntegrityConstraintViolationError is thrown when PostgreSQL responds with not_null_violation (23502) error.
Handling QueryCancelledError
QueryCancelledError is thrown when a query is cancelled by the user, i.e. pg_cancel_backend.
It should be safe to use the same connection if the QueryCancelledError is handled, e.g.
await pool.connect(async (connection0) => {
await pool.connect(async (connection1) => {
const backendProcessId = await connection1.oneFirst(sql`SELECT pg_backend_pid()`);
setTimeout(() => {
connection0.query(sql`SELECT pg_cancel_backend(${backendProcessId})`)
}, 2000);
try {
await connection1.query(sql`SELECT pg_sleep(30)`);
} catch (error) {
if (error instanceof QueryCancelledError) {
// Safe to continue using the same connection.
} else {
throw error;
}
}
});
});
Handling UniqueIntegrityConstraintViolationError
UniqueIntegrityConstraintViolationError is thrown when PostgreSQL responds with unique_violation (23505) error.
Types
This package is using Flow types.
Refer to ./src/types.js.
The public interface exports the following types:
DatabaseConnectionTypeDatabasePoolConnectionTypeDatabaseSingleConnectionType
Use these types to annotate connection instance in your code base, e.g.
// @flow
import type {
DatabaseConnectionType
} from 'slonik';
export default async (
connection: DatabaseConnectionType,
code: string
): Promise<number> => {
const countryId = await connection.oneFirst(sql`
SELECT id
FROM country
WHERE code = ${code}
`);
return countryId;
};
Debugging
Logging
Slonik uses roarr to log queries.
To enable logging, define ROARR_LOG=true environment variable.
By default, Slonik logs only connection events, e.g. when connection is created, connection is acquired and notices.
Query-level logging can be added using slonik-interceptor-query-logging interceptor.
Capture stack trace
Note: Requires slonik-interceptor-query-logging.
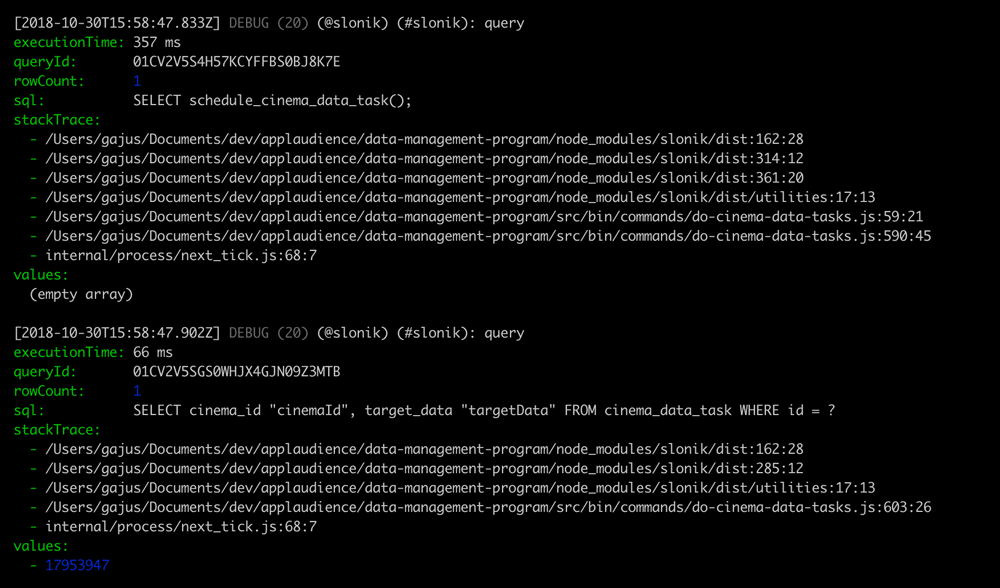
Enabling captureStackTrace configuration will create a stack trace before invoking the query and include the stack trace in the logs, e.g.
{"context":{"package":"slonik","namespace":"slonik","logLevel":20,"executionTime":"357 ms","queryId":"01CV2V5S4H57KCYFFBS0BJ8K7E","rowCount":1,"sql":"SELECT schedule_cinema_data_task();","stackTrace":["/Users/gajus/Documents/dev/applaudience/data-management-program/node_modules/slonik/dist:162:28","/Users/gajus/Documents/dev/applaudience/data-management-program/node_modules/slonik/dist:314:12","/Users/gajus/Documents/dev/applaudience/data-management-program/node_modules/slonik/dist:361:20","/Users/gajus/Documents/dev/applaudience/data-management-program/node_modules/slonik/dist/utilities:17:13","/Users/gajus/Documents/dev/applaudience/data-management-program/src/bin/commands/do-cinema-data-tasks.js:59:21","/Users/gajus/Documents/dev/applaudience/data-management-program/src/bin/commands/do-cinema-data-tasks.js:590:45","internal/process/next_tick.js:68:7"],"values":[]},"message":"query","sequence":4,"time":1540915127833,"version":"1.0.0"}
{"context":{"package":"slonik","namespace":"slonik","logLevel":20,"executionTime":"66 ms","queryId":"01CV2V5SGS0WHJX4GJN09Z3MTB","rowCount":1,"sql":"SELECT cinema_id \"cinemaId\", target_data \"targetData\" FROM cinema_data_task WHERE id = ?","stackTrace":["/Users/gajus/Documents/dev/applaudience/data-management-program/node_modules/slonik/dist:162:28","/Users/gajus/Documents/dev/applaudience/data-management-program/node_modules/slonik/dist:285:12","/Users/gajus/Documents/dev/applaudience/data-management-program/node_modules/slonik/dist/utilities:17:13","/Users/gajus/Documents/dev/applaudience/data-management-program/src/bin/commands/do-cinema-data-tasks.js:603:26","internal/process/next_tick.js:68:7"],"values":[17953947]},"message":"query","sequence":5,"time":1540915127902,"version":"1.0.0"}
Use @roarr/cli to pretty-print the output.
Syntax Highlighting
Atom Syntax Highlighting Plugin
Using Atom IDE you can leverage the language-babel package in combination with the language-sql to enable highlighting of the SQL strings in the codebase.
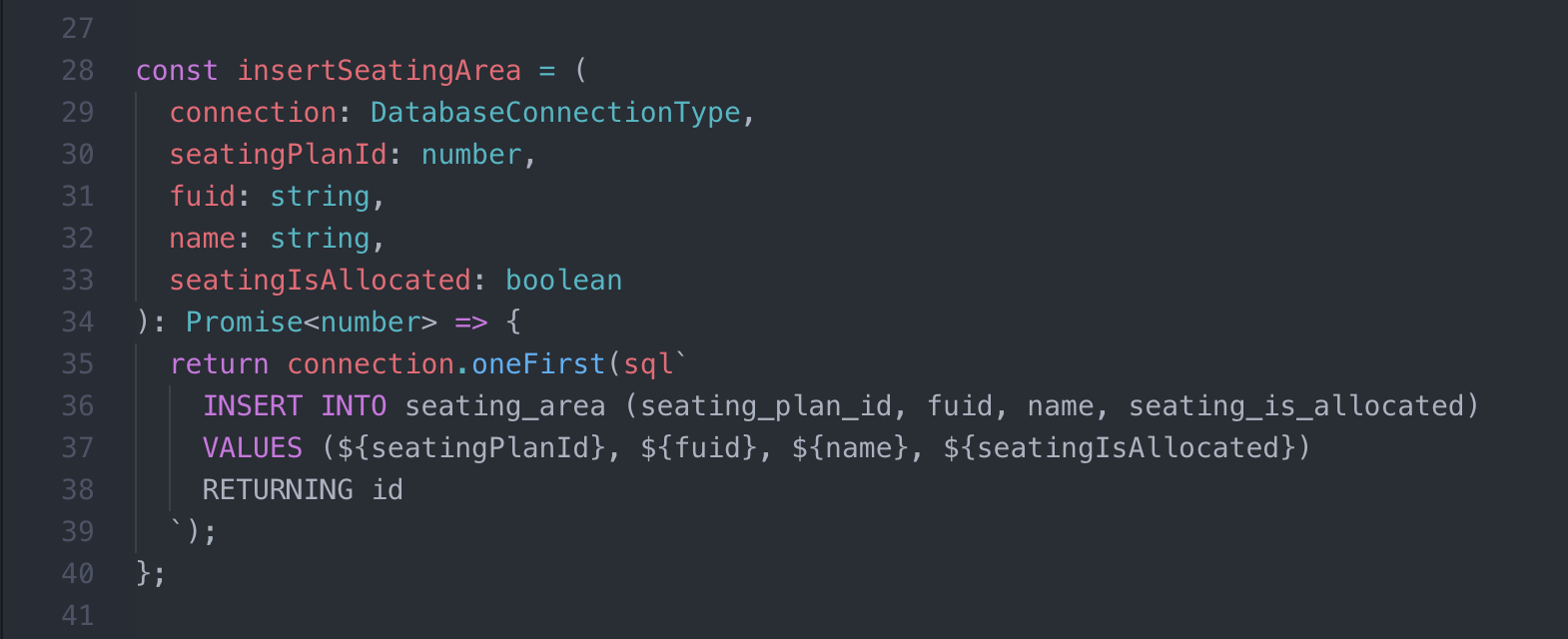
To enable highlighting, you need to:
- Install
language-babelandlanguage-sqlpackages. - Configure
language-babel"JavaScript Tagged Template Literal Grammar Extensions" setting to uselanguage-sqlto highlight template literals withsqltag (configuration value:sql:source.sql). - Use
sqlhelper to construct the queries.
For more information, refer to the JavaScript Tagged Template Literal Grammar Extensions documentation of language-babel package.
VS Code Syntax Highlighting Extension
The vscode-sql-template-literal extension provides syntax highlighting for VS Code: